Remaining useful life (RUL) is the amount of time a machine or an asset is likely to operate before it requires repair or replacement. Depending on your system, this time period can be represented in number of Days, Miles, Cycles or any other quantity. RUL prediction provides early warnings of failure and has become a key component in the prognostics and health management of systems. It allows engineers to schedule maintenance, optimize operating efficiency and avoid unplanned downtime.
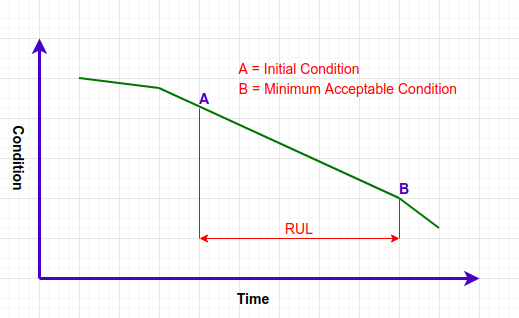
This image shows the deterioration of a machine over time. If A is the current condition and B is the minimum acceptable condition beyond which the machine will fail, Remaining Useful Life is computed as the time between these two points. If RUL is estimated in advance, maintenance or replacement can be carried out to avoid unplanned downtime and economic losses. Since the prediction of RUL is critical to operations and decision making, it is important to estimate it accurately.
This article focuses on predicting the Remaining Useful Life (RUL) using Machine Learning algorithms. The data set which we are using is provided by the Prognostics CoE at NASA Ames. It includes Run-to-Failure simulated data of Turbo Fan Jet engines. You can download the dataset from here. We will be using the following Python libraries –
Pandas, Numpy – Data manipulation and analysis
Sklearn – Machine Learning in Python
Matplotlib, Seaborn – Data Visualisation
The data set is divided into training and test subsets. The engine is operating normally at the start of each time series and develops a fault at some point during the series. In the training set, the fault grows in magnitude until system failure. In the test set, the time series ends sometime before system failure. Our goal is to predict the number of remaining operational cycles before failure in the test set, i.e., the number of operational cycles after the last cycle that the engine will continue to operate. The dataset also provides a vector of true RUL values for the test data.
Exploratory Data Analysis :
The data is provided as a text file with 26 columns of numbers, separated by spaces. Each row is a snapshot of data taken during a single operational cycle and each column is a different variable. The columns correspond to :
1 – Unit Number
2 – Time in cycles
3 to 5 – Operational Settings
6 to 28 – Sensor Measurements
The data is loaded in a dataframe using Pandas library. The last 2 columns contain only NaN (Not a Number) values. Hence they are dropped from the dataframe. The next step is to generate descriptive statistics like count, mean, minimum and maximum for each column. This gives us an idea regarding the distribution of values present in the column. We can drop the features which have a constant mean, min, max values as their presence doesn’t affect the target (RUL) values.
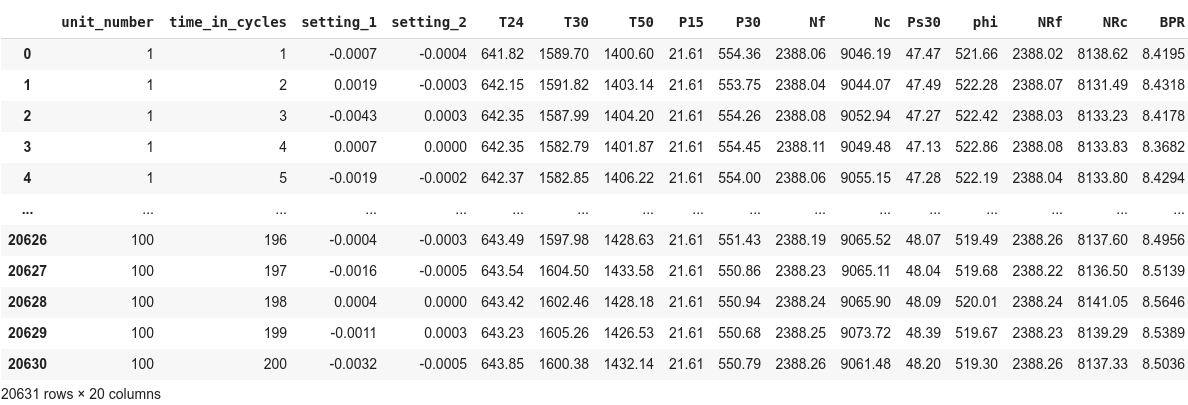
This is the final data frame comprising 20631 records and 20 columns. The next step is to create an additional column ‘RUL’ showing the number of cycles to failure for each record in the training data. First we will group the data by ‘unit_number’ and find the maximum value of ‘time_in_cycles’ for that ‘unit_number’. For every record, ‘RUL’ is the difference between this max value and ‘time_in_cycles’ value. That will be our target variable for the Machine Learning models.
In any Data Science project, checking correlations is an important part of the exploratory data analysis process. It is one of the methods to decide which features affect the target variable the most. In other words, it’s a commonly used method for feature selection in Machine Learning. A heatmap is a 2-D graphical representation of data where the individual values that are contained in a matrix are represented as colours. The seaborn python package allows the creation of annotated heatmaps.
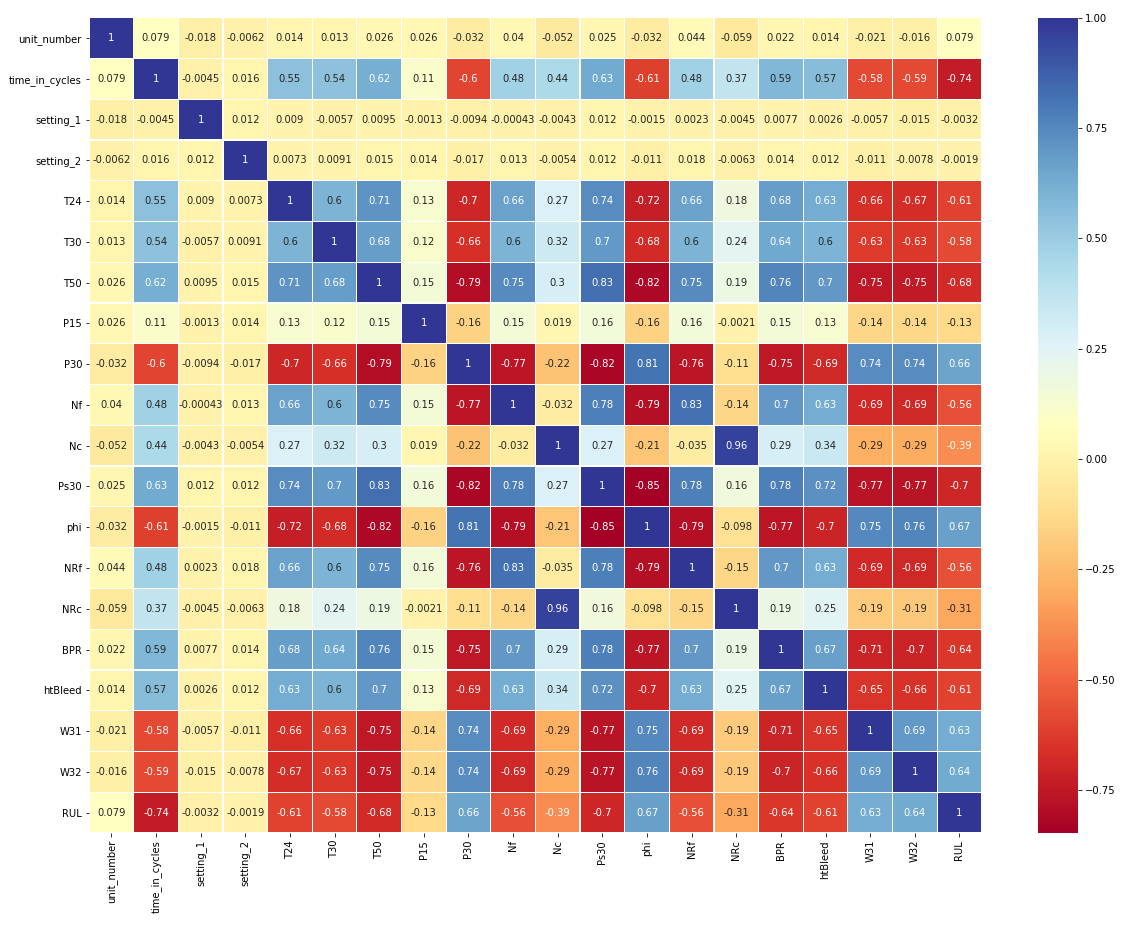
The above correlation matrix shows that the columns unit_number, setting_1, setting_2 are weakly correlated with target variable RUL. Also the features Nc and NRc are highly correlated with each other (correlation coefficient 0.96). Hence we drop one (Nc) and the weakly correlated features.
Model Training :
We will train the model on the training dataset and test its accuracy on the testing dataset for which we have been provided with true RUL values. All the columns except ‘RUL’ are the features (independent variables) and ‘RUL’ is the target (dependent) variable. The algorithms which we will use are –
RandomForestRegressor – A Random Forest is an ensemble technique capable of performing both regression and classification tasks with the use of multiple decision trees and a technique called Bootstrap and Aggregation, commonly known as Bagging. The basic idea behind this is to combine multiple decision trees in determining the final output rather than relying on individual decision trees. In the case of regression, the final output is the mean of all the outputs.
XGBRegressor – XGBoost (Extreme Gradient Boosting) is a popular supervised machine learning model with characteristics like fast computation, parallelization, and better performance. Boosting is an ensemble technique where new models are added to correct the errors made by existing models. It combines a set of weak learners and delivers improved prediction accuracy. The outcomes predicted correctly are given a lower weight while the others are weighted higher.
Model Testing :
From the test data, we need to keep only the features used while training. In the test set, the time series ends sometime before system failure and our goal is to predict the number of remaining operational cycles before the engine breaks down. We will further filter the test set and keep the records with maximum value of time_in_cycles for every engine.
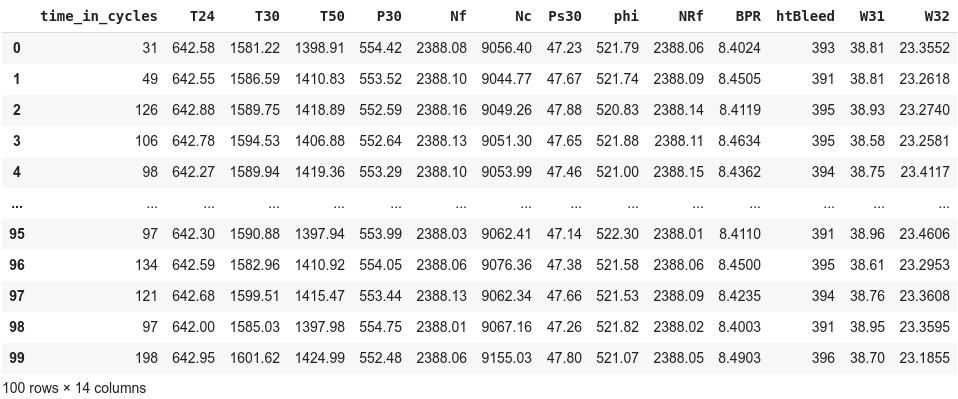
This is the final test data. For a particular record (let’s say the record with index = 0) we have data till the 31st cycle and we have to predict the number of operational cycles after the last cycle that the engine will continue to operate. To know how good our model is performing, we will calculate mean absolute error, mean squared error and r2 score between the predicted values and true RUL values. The results are –
Mean absolute error – 19.25
Root mean squared error – 24.45219826518671
R2 score – 0.65
R2 score tells us what percentage of the total variation in independent variables is described by variation in dependent variables.
R-squared = Explained variation / Total variation
It is a statistical measure of how close the data is to the fitted regression line and is always between 0 and 1
- 0 indicates that the model explains none of the variability of the response data around its mean.
- 1 indicates that the model explains all the variability of the response data around its mean.
Next we will plot a graph of predicted and actual RUL values using matplotlib library
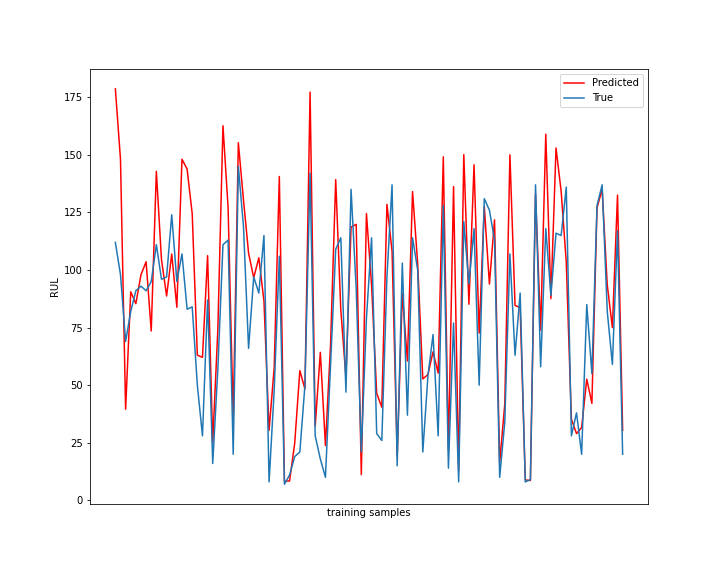
As we can see in the above graph, the model is not able to capture some values. This is because the sensor data is very noisy. One way to improve the model’s performance and reduce error is as follows –
We will make predictions on not just the last slice of sensor values but an optimized number of previous records (say last 5) from the test set. Then we will take the mean of all the predictions to get the final RUL value.
Using this we get the following results –
Mean absolute error – 14.83
Root mean squared error – 20.45116133621756
R2 score – 0.76
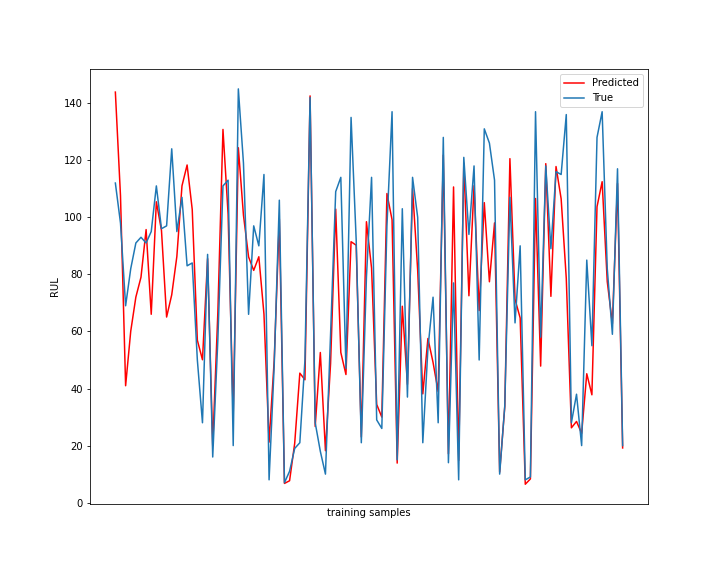
As we can see, the results using this technique are better than previous. R2 score improved considerably and errors reduced as well. We can also try other Machine Learning algorithms or modify hyper parameters of existing algorithms to further improve the results.