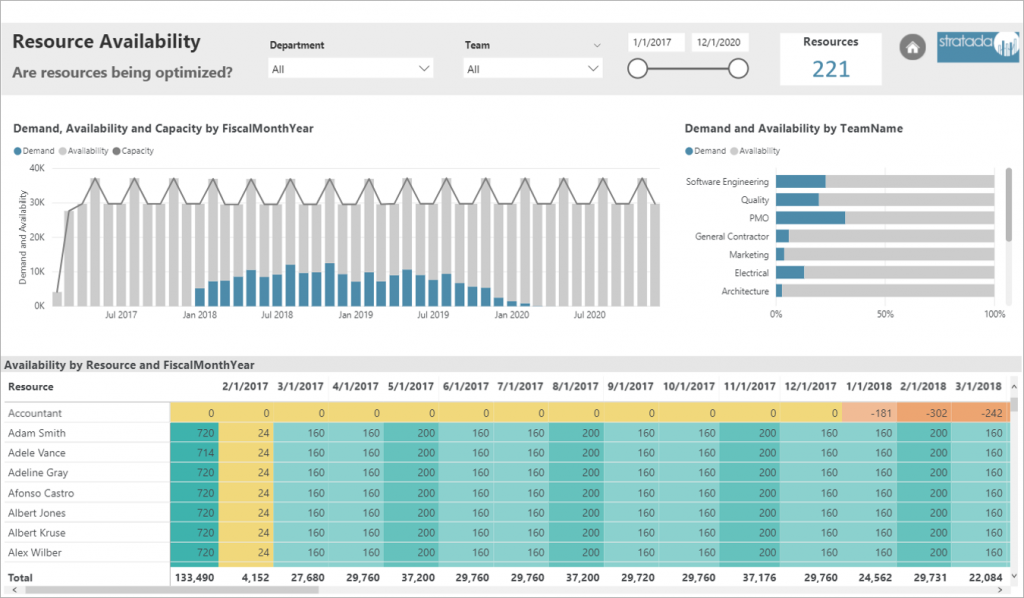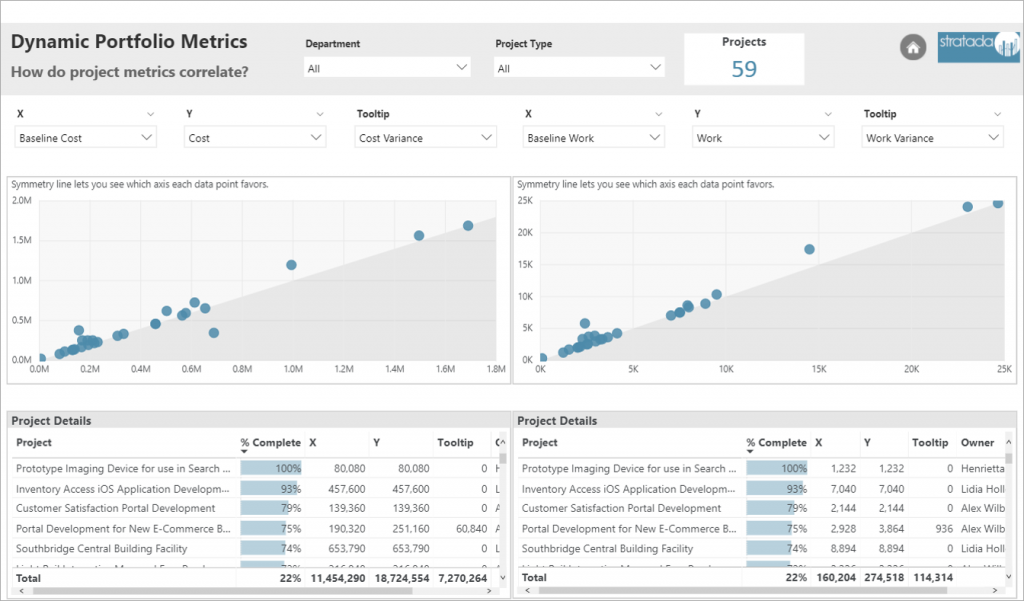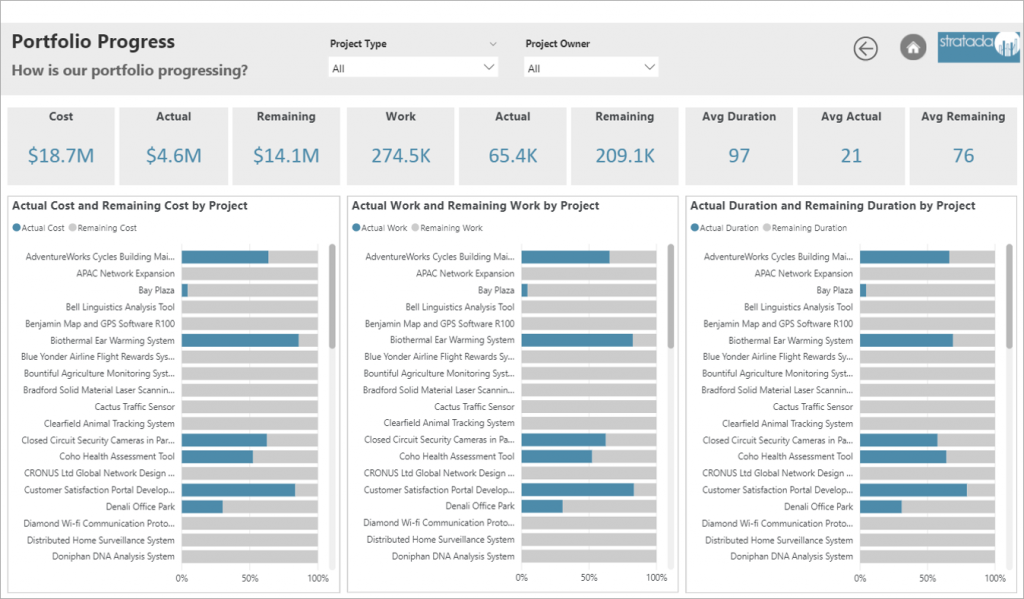
Jira is part of a family of products designed to help teams manage their work. It is used by organizations for bug / issue tracking and agile project management. One entity of this tool is an ‘Issue’ which can be a bug, task or something else depending upon the way an organization uses this application.
A particular issue can have loads of information associated with it, for example – description, issue type, date of creation, current status, resolution etc. Finding patterns in such data can help to solve potential problems, increase efficiency of using Jira and provide significant insights on the projects and people of the organization.
There is a library in python by the name Python Jira which allows easy communication with Jira APIs. JQL (Java Query Language) is a powerful and flexible way to search for issues in Jira. JQL can be used along with Python Jira library to read the data of a particular issue or extract several issues at one time. After reading this information, it can be saved in a ‘csv’ file. This csv file can be directly loaded into Power BI for analysis and visualization. The following image shows few of the columns and data utilized in this article:
Radial Bar Chart
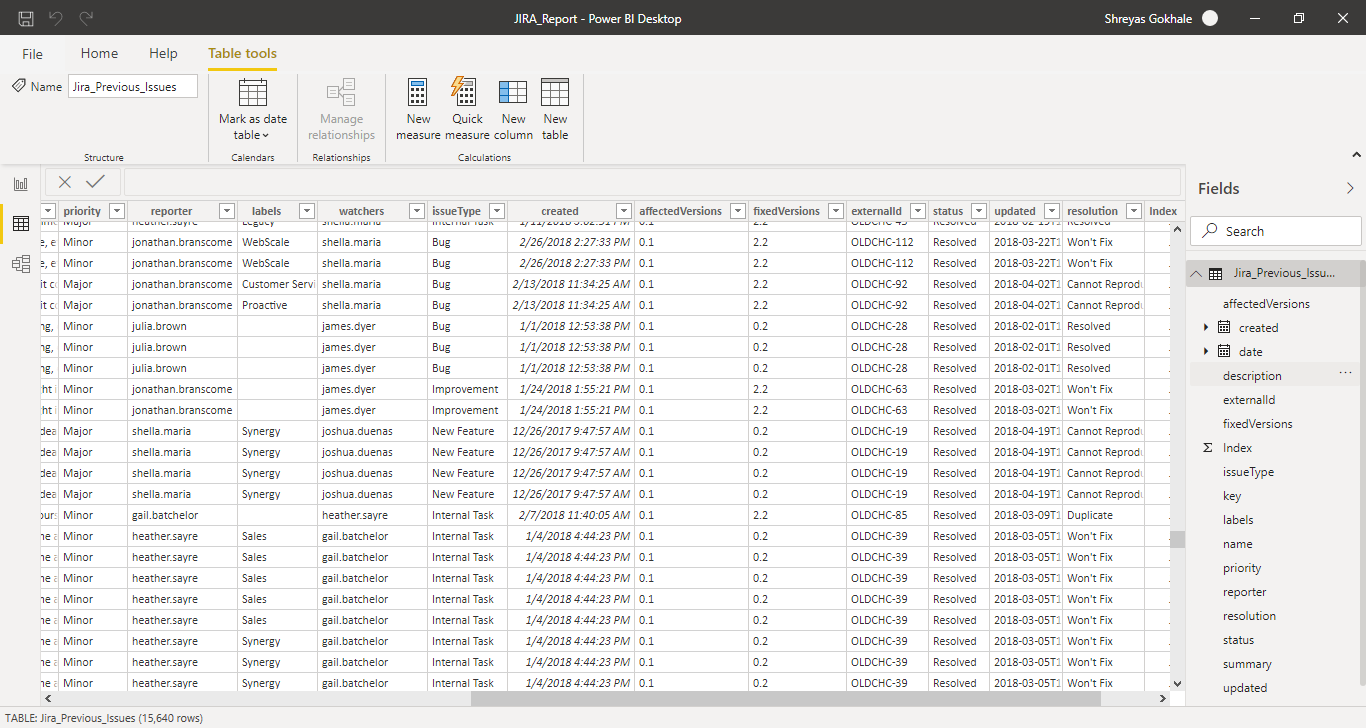
The following custom Radial Bar Chart made using Matplotlib shows the distribution of the Issues according to their Status. Slicers for Name and Reporter are added directly in PowerBI.
This selects the filtered rows from the dataset. The total number of issues for each status are then calculated and transformed into a pandas dataframe. This is used as input for the radial bar chart.
Larger the arc length, more the issues of that type. The above plot shows that the percentage of issues with status ‘Open’ is more than other types for the reporter angela.gant.
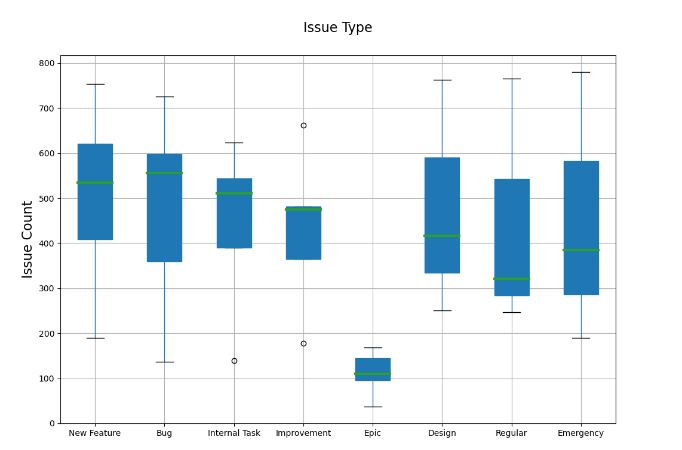
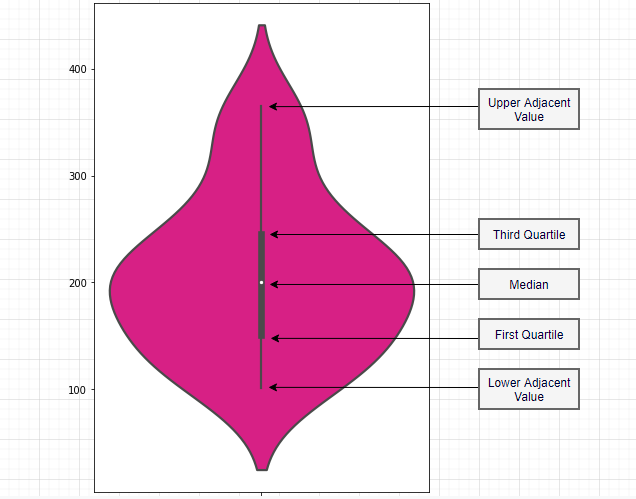
Box Plot
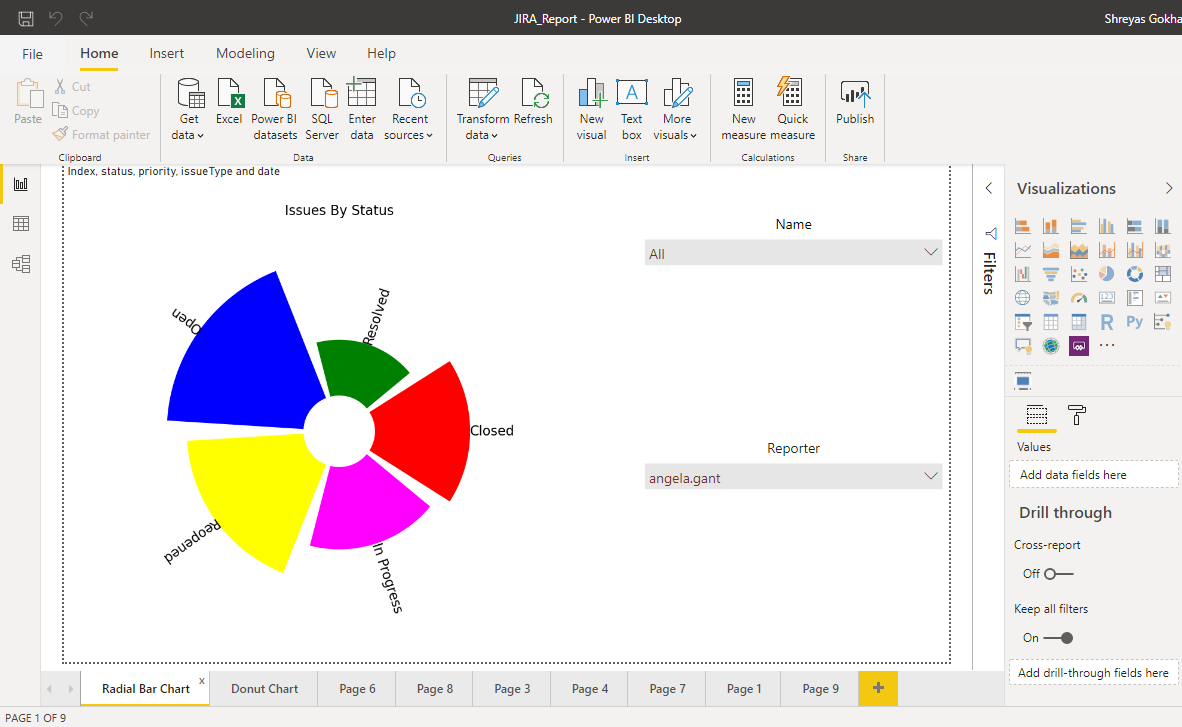
A boxplot is a standardized way of displaying the distribution of data based on a five number summary (minimum, first quartile (Q1), median, third quartile (Q3) and maximum). It tells us if the data is symmetrical and the presence of any outliers. Following image helps in understanding the general structure of a boxplot:

Boxplots have the advantage of taking up less space than histogram or density plot and are useful when comparing distributions between many groups. Beyond the basic information, the mean of data and it’s confidence level can also be shown in a diamond shape inside the box. Another advantage of box plots is that they can show outliers unlike many other data display methods.
The boxplot below is created using matplotlib. First, the dataset is divided into data frames of each month based on the ‘date’ column. The number of issues of each type (New Feature, Bug etc.) for each month are added up. Then these are combined into a single dataframe and given as input to the boxplot. While making a boxplot, the ‘NaN’ values present in the dataset are ignored by default. The small circles are the outliers.
Density Plot
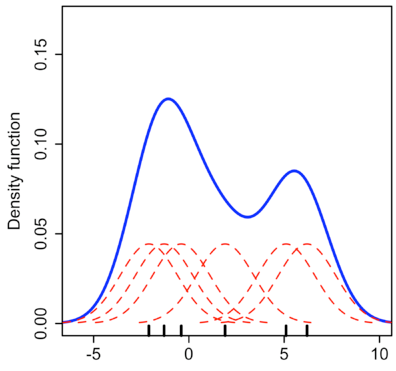
The density plot is created using seaborn library. It visualizes the distribution of data over a continuous interval or time period. This chart is a variation of a Histogram that uses kernel smoothing to plot values, allowing for smoother distributions by smoothing out the noise. The kernel most often used is a Gaussian. The peaks of a Density Plot help display where values are concentrated over the interval. For better understanding, have a look at the following plot:
Drleft at English Wikipedia CC BY-SA 3.0
The small black vertical lines on x-axis represent the data points. The individual kernels (Gaussians in this example) are shown drawn in dashed red lines above each point. The solid blue curve is created by summing the individual Gaussians and forms the overall density plot. The x-axis is the value of the variable. The y-axis in a density plot is the probability density (probability per unit on x-axis) function for the kernel density estimation.
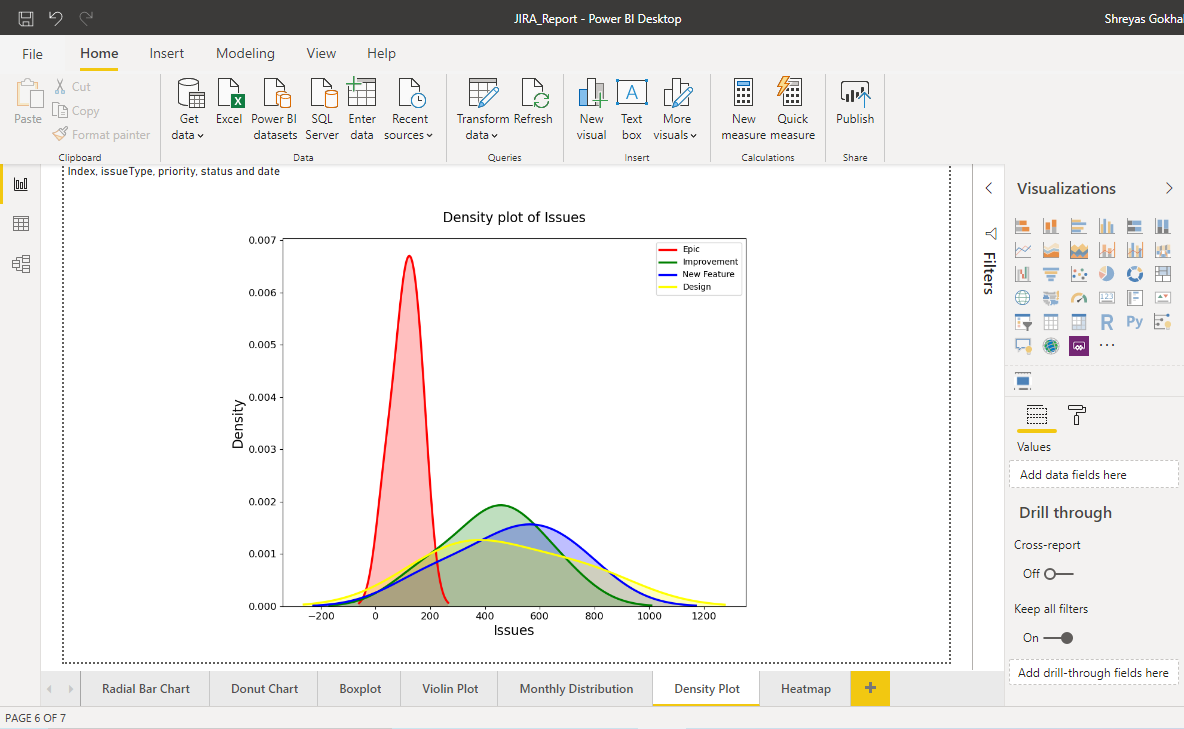
The above figure shows a density plot of 4 different Issues. To make density plots in seaborn, distplot or kdeplot function can be used. In this case, the distplot function is used to make multiple distributions with one function call. The density plot has a parameter called the bandwidth that changes the individual kernels and significantly affects the final result of the plot. The plotting library will choose a reasonable value of the bandwidth (by default using the ‘scott’ estimate).
Violin Plot
The Violin plot is created using the seaborn library in python. It can be considered as a combination of box plot and kernel density plot. It shows the distribution of quantitative data across several levels of one (or more) categorical variables such that those distributions can be compared. Unlike a box plot, in which all of the plot components correspond to actual data points, the violin plot features a kernel density estimation of the underlying distribution. The structure of violin plot is explained in following diagram:
Boxplots show medians, ranges and variabilities effectively and allow comparing groups of different sizes. But sometimes they can be misleading. They are not affected by data’s distribution. When the data “morph” but manage to maintain their stat summaries (medians and ranges), their box plots stay the same. This is where violin plots come to the rescue because the “violin” shape of a violin plot comes from the data’s density plot. When there are too many groups, their overlapping density plots become difficult to read. This doesn’t happen with violin plots, because they don’t sit on top of one another. They are placed side by side which makes them easier to read.
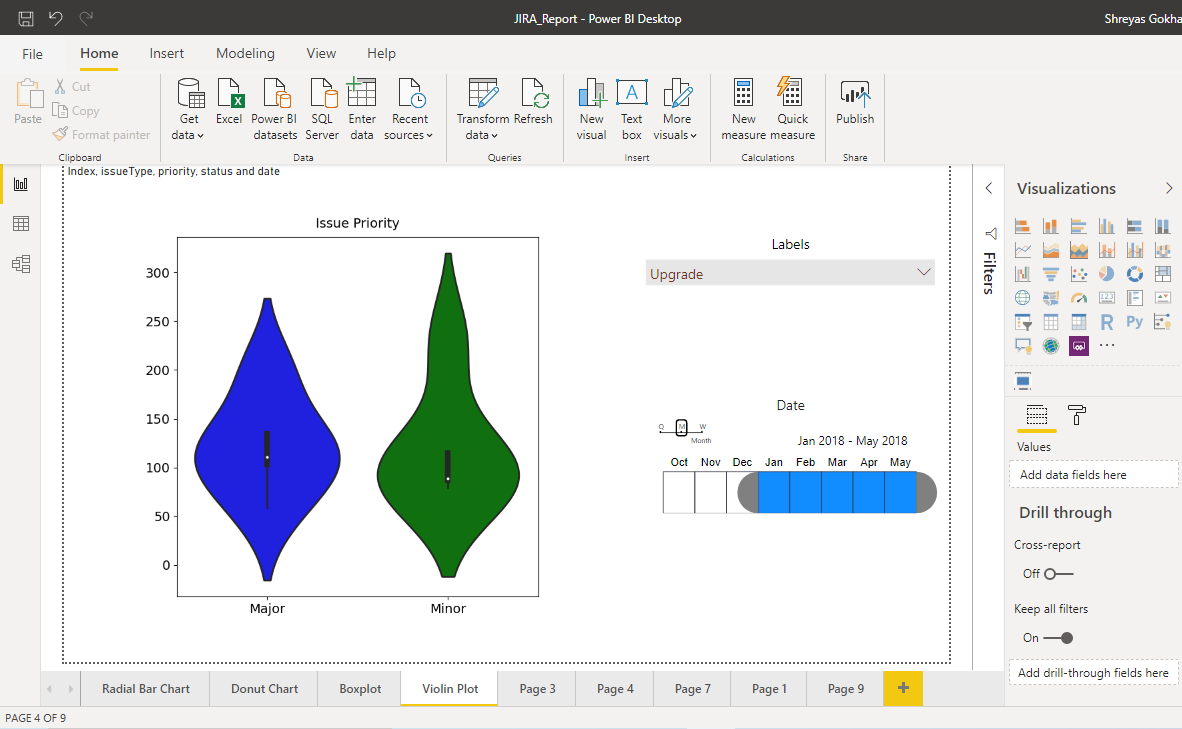
The visualization above is a violin plot based on the priority of the Issues (Major, Minor). Slicers for Labels and Date are added directly in PowerBI. This helps is knowing the distribution of the priority of the Issues for the selected Label over the desired time period.
Dismissed Donut Chart
The Dismissed Donut Chart is a variation of the Donut Chart. It is being used to visualize the final Resolution of the Issues. The steps for creating this are as follows –
- Calculate the number of data points
- Find the max value in the dataset for full ring
- Set radius of the plot
- Calculate width of each ring and create colors along a chosen colormap
- Create rings in donut chart
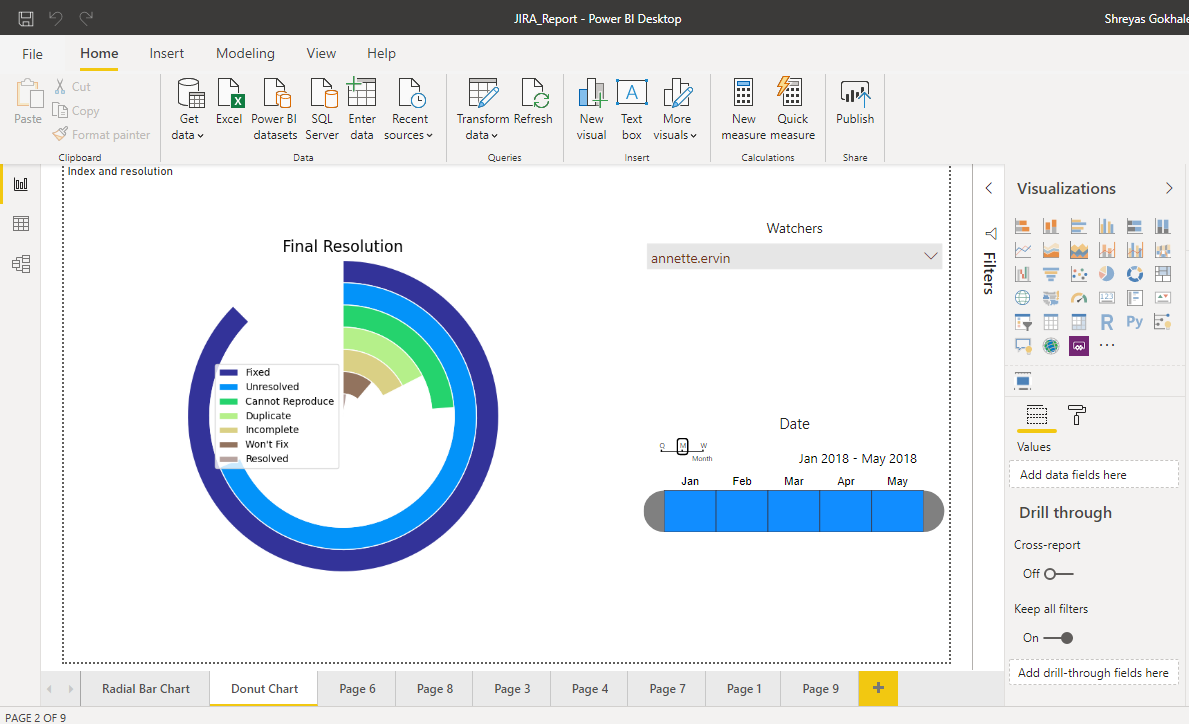
Slicers for Watchers and Date are added directly in PowerBI. JIRA makes it easy to keep others in the loop and stay on top of the issues. This visualization shows the distribution of the resolutions for a particular watcher over the selected time period. A watcher is someone who gets a complete set of notifications during the entire lifecycle of the issue. Watching helps a person stay connected to that issue from the point of discovery all the way to resolution.
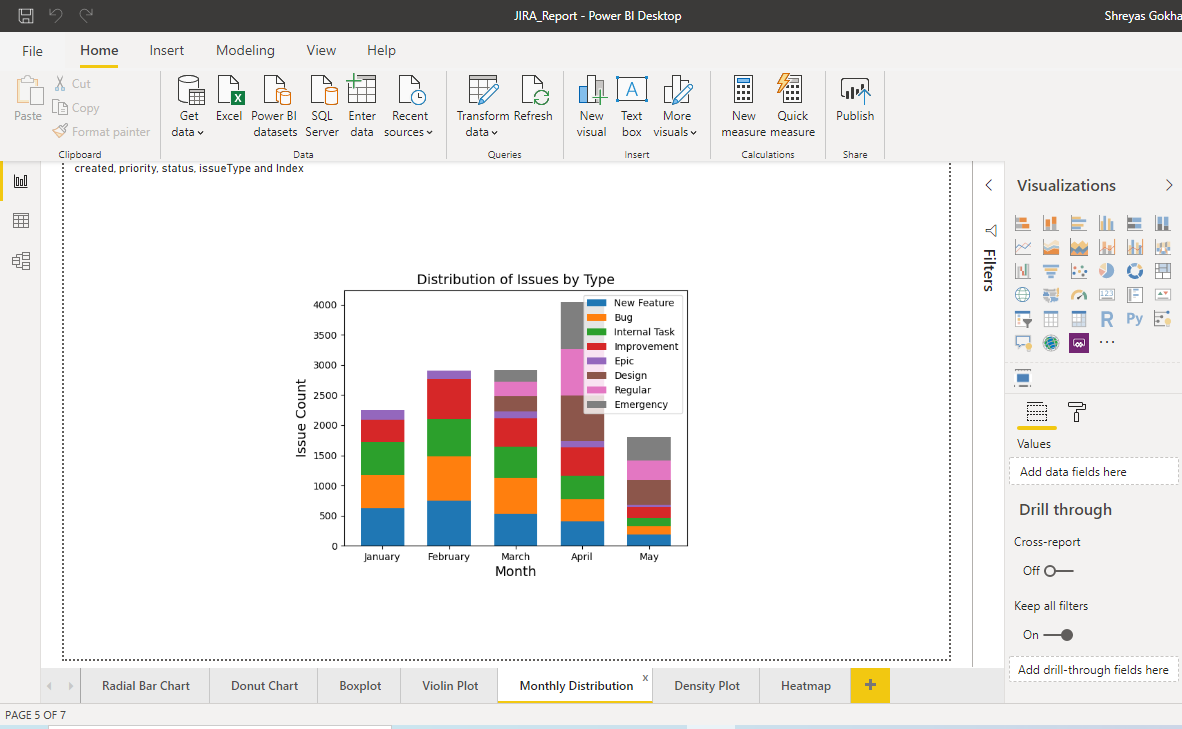
Stacked Bar Chart
The following stacked bar chart shows monthly distribution of the type of Issues. Each bar in the chart represents a whole, and segments in the bar represent different parts or categories of that whole. Different colors are used to illustrate the different categories in the bar. They can be made with a few lines of code using matplotlib library in python and are easy to interpret.